What's the most popular car in the UK?
The Office of National Statistics is a brilliant source of interesting data sets. This page lists recently released datasets. Check regularly and you’ll soon notice these data sets feed into news articles by the Economist, BBC news and more.
One I recently thought to explore detailed the count of car makes and models in the UK. I wonder what’s the most popular car make and model in the UK?
library(tidyverse)
library(readxl)
library(stringr)
path <- "~/Learning/R/Datasets/vehicle-statistics-make-model.xlsx"
car_data <- read_excel(path = path, skip = 8, col_names = FALSE, sheet = 1)Great, we’ve got our data. But what does it look like?
| X__1 | X__2 | X__3 | X__4 | X__5 | X__6 | X__7 | X__8 | X__9 | X__10 | X__11 | X__12 | X__13 | X__14 | X__15 | X__16 | X__17 | X__18 | X__19 | X__20 | X__21 | X__22 | X__23 | X__24 | X__25 | X__26 | X__27 | X__28 | X__29 | X__30 | X__31 | X__32 | X__33 | X__34 | X__35 | X__36 | X__37 | X__38 | X__39 | X__40 | X__41 | X__42 | X__43 | X__44 | X__45 | X__46 | X__47 | X__48 | X__49 | X__50 | X__51 | X__52 | X__53 | X__54 | X__55 | X__56 | X__57 | X__58 | X__59 | X__60 | X__61 | X__62 | X__63 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ABARTH | 124 SPIDER MULTIAIR AUTO | 72 | 71 | 59 | 58 | 36 | 35 | 26 | 25 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| ABARTH | 500 | 4456 | 4382 | 4447 | 4370 | 4490 | 4411 | 4525 | 4448 | 4568 | 4487 | 4550 | 4469 | 4580 | 4500 | 4574 | 4494 | 4548 | 4467 | 4462 | 4387 | 4421 | 4347 | 4263 | 4094 | 3977 | 3834 | 3782 | 3622 | 3535 | 3387 | 3296 | 3148 | 2982 | 2752 | 2630 | 2417 | 2293 | 2055 | 1909 | 1677 | 1358 | 1039 | 706 | 456 | 232 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| ABARTH | 500 C | 608 | 596 | 608 | 598 | 603 | 592 | 614 | 602 | 615 | 604 | 614 | 603 | 631 | 619 | 627 | 615 | 638 | 624 | 640 | 626 | 640 | 626 | 640 | 648 | 642 | 628 | 604 | 587 | 560 | 520 | 499 | 455 | 401 | 342 | 316 | 239 | 190 | 127 | 74 | 2 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| ABARTH | 500 CUSTOM | 367 | 362 | 363 | 358 | 374 | 370 | 382 | 378 | 378 | 373 | 380 | 376 | 380 | 376 | 373 | 369 | 329 | 326 | 196 | 196 | 16 | 16 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| ABARTH | 500 CUSTOM S-A | 112 | 110 | 112 | 110 | 114 | 112 | 113 | 111 | 111 | 109 | 89 | 87 | 57 | 55 | 26 | 26 | 18 | 18 | 15 | 15 | 2 | 2 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| ABARTH | 500 S-A | 90 | 88 | 87 | 85 | 92 | 90 | 92 | 90 | 94 | 92 | 96 | 94 | 95 | 93 | 95 | 93 | 90 | 88 | 82 | 80 | 78 | 76 | 71 | 62 | 55 | 48 | 43 | 35 | 24 | 15 | 8 | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA | NA |
| oh. |
oh no.
It’s not as we’d like it, but we can certainly handle it.
We’ll need to tidy it up a little before the real fun begins.
names <- read_excel(path = path, skip = 6, col_names = F, n_max = 1)
names[2] <- "Model"
names(car_data) <- names
tidy_cars <- car_data %>%
gather(key = Period, value = Count, -Make, -Model) %>%
extract(Period, c("Year", "Quarter", "Region"), "(\\d{4}) Q(1|2|3|4) (UK|GB)") %>%
mutate(Year = as.integer(Year),
Quarter = as.integer(Quarter),
Make = str_trim(Make),
Model = str_trim(Model),
YQ = lubridate::yq(paste(Year,"/",Quarter))) %>%
filter(stringr::str_length(Make) < 20,
!is.na(Count))| Make | Model | Year | Quarter | Region | Count | YQ |
|---|---|---|---|---|---|---|
| ABARTH | 124 SPIDER MULTIAIR AUTO | 2017 | 2 | UK | 72 | 2017-04-01 |
| ABARTH | 500 | 2017 | 2 | UK | 4456 | 2017-04-01 |
| ABARTH | 500 C | 2017 | 2 | UK | 608 | 2017-04-01 |
| ABARTH | 500 CUSTOM | 2017 | 2 | UK | 367 | 2017-04-01 |
| ABARTH | 500 CUSTOM S-A | 2017 | 2 | UK | 112 | 2017-04-01 |
| ABARTH | 500 S-A | 2017 | 2 | UK | 90 | 2017-04-01 |
Much better!
Now that we have our tidy dataset, lets explore the latest counts in the UK, from Q2 2017.
tidy_cars %>%
filter(Year == 2017, Quarter == 2, Region == "UK") %>%
count(Make, wt = Count) %>%
arrange(desc(n)) %>%
top_n(n, n = 30) %>%
ggplot(aes(reorder(Make, n), n)) +
geom_bar(stat = "identity") +
labs(x = "Make", y = "Count",
title = "The 30 most popular car makes in the UK as of Q2 2017",
subtitle = "Ford, Vauxhal and Volkswagen are significantly more popular than other makes") +
coord_flip() + scale_y_continuous(labels = scales::comma)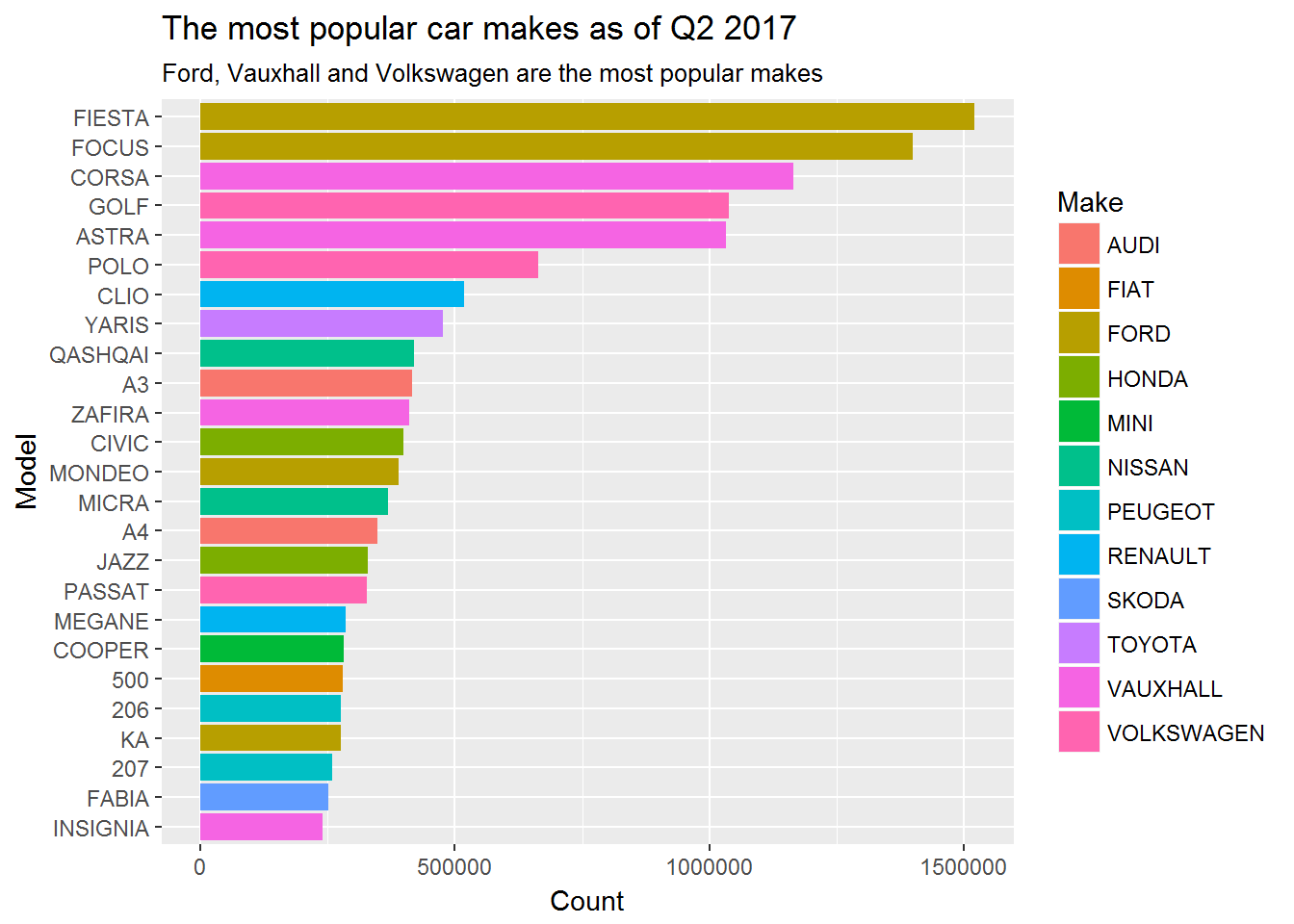
Most popular car models (by Manufacturer)
Before we can find which car models are most popular, we need to do a bit of data transformation first. To illustrate the problem, look out the output below.
tidy_cars %>%
select(Make, Model) %>%
filter(Make == "FORD", grepl("B-MAX", Model)) %>%
distinct() %>%
knitr::kable()| Make | Model |
|---|---|
| FORD | B-MAX STUDIO |
| FORD | B-MAX TITANIUM AUTO |
| FORD | B-MAX TITANIUM NAVIGATOR |
| FORD | B-MAX TITANIUM NAVIGATOR AUTO |
| FORD | B-MAX TITANIUM NAVIGATOR TDCI |
| FORD | B-MAX TITANIUM TDCI |
| FORD | B-MAX TITANIUM TURBO |
| FORD | B-MAX TITANIUM X |
| FORD | B-MAX TITANIUM X AUTO |
| FORD | B-MAX TITANIUM X NAV TDCI |
| FORD | B-MAX TITANIUM X NAVIGATOR |
| FORD | B-MAX TITANIUM X NAVIGATOR A |
| FORD | B-MAX TITANIUM X TDCI |
| FORD | B-MAX ZETEC |
| FORD | B-MAX ZETEC AUTO |
| FORD | B-MAX ZETEC NAVIGATOR |
| FORD | B-MAX ZETEC NAVIGATOR AUTO |
| FORD | B-MAX ZETEC NAVIGATOR TDCI |
| FORD | B-MAX ZETEC RED EDITION |
| FORD | B-MAX ZETEC RED EDITION AUTO |
| FORD | B-MAX ZETEC SILVER EDITION |
| FORD | B-MAX ZETEC SILVER EDITION A |
| FORD | B-MAX ZETEC TDCI |
| FORD | B-MAX ZETEC TURBO |
| FORD | B-MAX ZETEC WHITE EDITION |
| FORD | B-MAX ZETEC WHITE EDITION AUTO |
When we consider Car models, should we group similar models together, or consider them separate? If we don’t group them, a popular car model with many different sub-models may appear less popular that it is overall.
For our purposes, we will group them together the best we can. This should gives us a more representative picture of car model popularity. The downside is that our grouping is arbitary. The strategy I’ve taken is to split the strings on the first space, and take the first chunk. This works for the majority of cases, but still misses some.
# helper function to split Model on the first " " and extract the first chunk
simplify_model <- function(model) {
split_list <- stringr::str_split(model, " ") %>% `[[`(1)
split_list[[1]]
}tidy_cars %>%
filter(Year == 2017, Quarter == 2, Region == "UK") %>%
mutate(simple_model = map_chr(Model, ~ simplify_model(.x))) %>%
group_by(Make, simple_model) %>%
summarise(Count = sum(Count)) %>%
ungroup() %>%
top_n(25, Count) %>%
ggplot(aes(x = (reorder(simple_model, Count)), y = Count, fill = Make)) +
geom_bar(stat = "identity") +
scale_y_continuous(labels = scales::comma) +
labs(x = "Model",
y = "Count",
title = "The most popular car makes as of Q2 2017",
subtitle = "Ford, Vauxhall and Volkswagen are the most popular makes") +
coord_flip() 